Couple of weeks ago SQLd360 v1 came out and now v3, so what happened to v2? It was a “silent” release to fix a bug and sneak in a couple features I didn’t complete in time for v1 but most of the new features are in v3.
The main page now looks something like this
so the list of content grew a bit and it will keep growing release after release.
List of bugs (hopefully) shrank as well but no promise on that 🙂
The major additions are
- Plan Control section reporting info about SQL Profiles, SQL Plan Baselines and SQL Patches
- Execution plans details from SQL Plan Baselines
- Time series report/chart for average and median elapsed for the SQL (regardless of the plan), this can help answer the question “how is my SQL doing over time?”
- Time series report/chart for average elapsed time per plan hash value for the SQL, this can help identify if a change in performance is caused by a plan change
- A standalone script to execute the SQL from SQL*Plus, the script includes bind variables definition/assignment in case the SQL has binds
- Cursor Sharing section reporting info from GV$SQL_SHARED_CURSOR
- Bind datatype mismatch report, this can help identify those cases where apps define binds for the same SQL using different datatypes
plus some other minor reports/tweaks.
Bug fixes here and there, specially in the histograms section where now every endpoint value is (AFAIK, if you see issues let me know so I can fix them!) properly converted and charted so we can leverage charts to analyze histograms 😀
Ie the following one is for SH.CUSTOMERS.CUST_YEAR_OF_BIRTH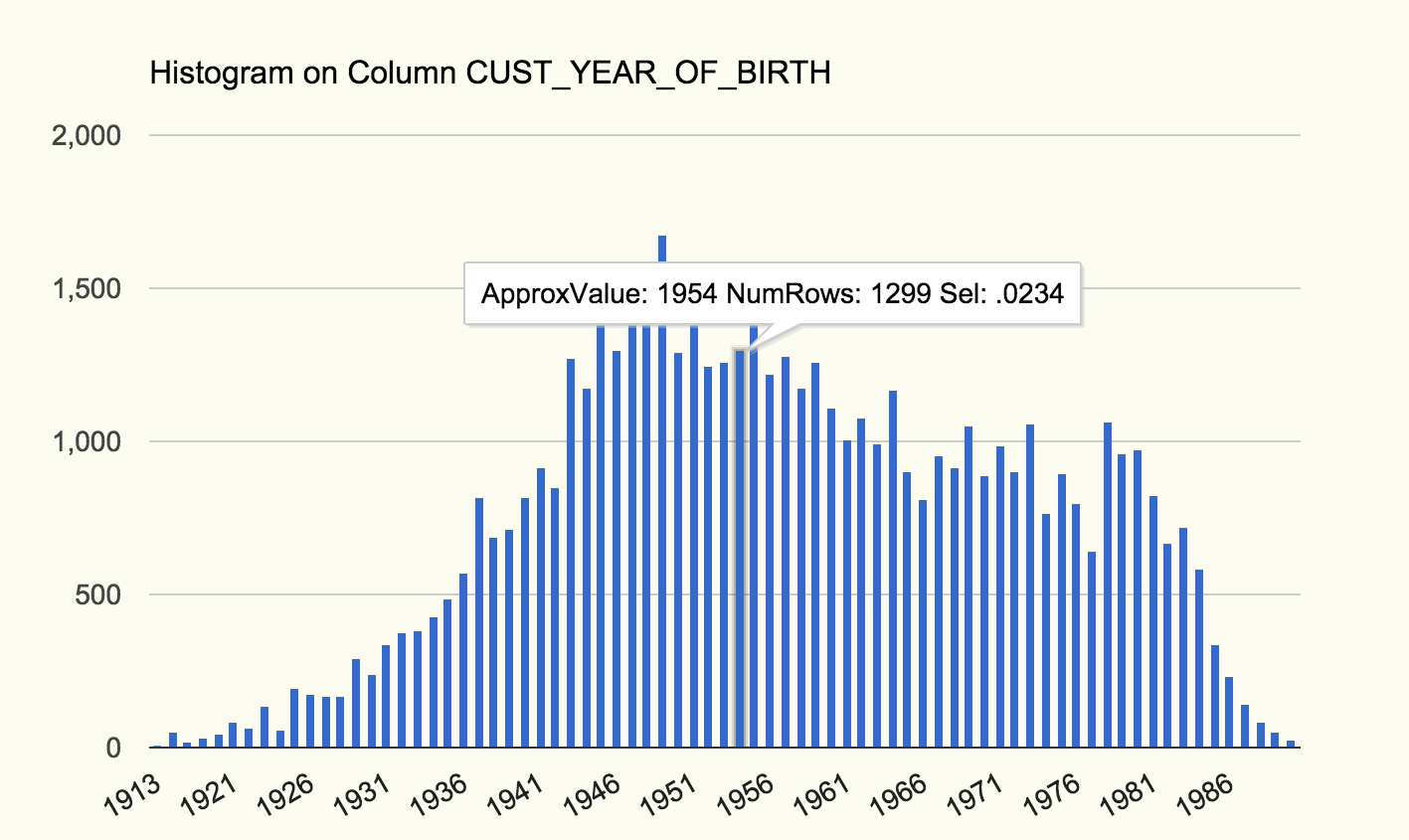
From the chart above we can see how the data is distributed and for each bar(/bucket) the (approximate) value, how many rows belong to each bucket and the selectivity for an equality predicate for that specific value.
More things in the work and as usual feedback/comments/reported issues are very much welcome!!!!

Pingback: SQLd360 v3 now available, new features and (hopefully) less bugs! | Christoph's 2 Oracle Cents
March 2, 2015 at 9:22 am
Hi Mauro,
excellent job as usual,but this works only with EE but not with SE, is it right ? Need a Tuning or Diagnostic pack. For the guys which use SE, is there something ?
Ciao
Alberto
LikeLike
March 2, 2015 at 12:09 pm
Ciao Alberto!
You can use SQLd360 with every level of licensing you have, including SE. Some info will be missing but some others will be there and (hopefully) still useful 🙂 Ie. One that I personally like a lot is the chart for histograms bucket, you would still get that as well as all the info coming from memory.
LikeLike
March 2, 2015 at 1:51 pm
Hi Mauro,
I just tryed in my SE and all works fine, the chart for histograms bucket it’s simply great !!! better than a thousand words… 😉
Thanks a lot for sharing
Another question, what about for RAC enviroment?
Alberto
LikeLike
March 2, 2015 at 3:28 pm
The tool extracts info from each node in RAC TOO (thanks GV$ :-). Glad to hear you like the charts!
LikeLike