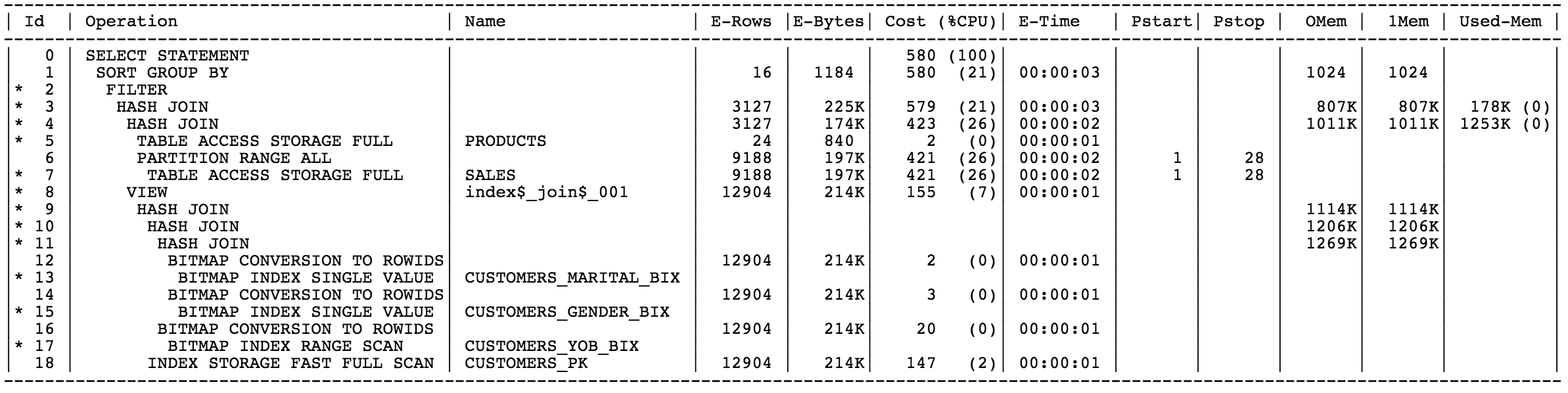
I think SQL Monitoring is one of the greatest addition to the Oracle performance diagnostics world since a long time ago (10046-time maybe?) because it allows to collect in a single shot a long list of crucial information that are otherwise painful to extract and put together. The report provides a complete picture of the execution across processes (PX), nodes (RAC), etc etc.
On the other hand, one of the major limitations (the biggest one, imho) is SQL Monitor info are quickly aged out of memory and not stored in AWR (there is no DBA_HIST_SQL_MONITOR or similar) so they are are unlikely to be around for a post-mortem investigation.
Good news is in 12c we can pull a report for a historical execution, granted the execution was expensive enough to candidate for collection. I didn’t investigate the details of the automatic collection yet but there are two ways, details from DBA_HIST_REPORTS_CONTROL:
- REGULAR – per-minute report capture subject to DBTIME budget
- FULL_CAPTURE – capture will be run per minute without the DBTIME budget constraints
The FULL_CAPTURE can be enabled using DBMS_AUTO_REPORT.START_REPORT_CAPTURE/FINISH_REPORT_CAPTURE.
Info about each automatically collected report are stored in DBA_HIST_REPORTS and the report itself (in XML format) is stored in DBA_HIST_REPORTS_DETAILS.
The whole framework is also used for Real-Time ADDM so the DBA_HIST_REPORTS* views are not organized in a SQL Monitor-friendly way (ie. SQL ID/SQL Exec ID/SQL Exec Start) but rather in a report-oriented way, the key is REPORT_ID.
Column COMPONENT_NAME helps track down the source of the report, “sqlmonitor” in this case.
A summary of the report is stored in REPORT_SUMMARY in XML format, so a simple SQL like the following pulls the list of REPORT_ID/SQL_ID (plus anything else you may want to extract from the summary, ie. SQL Exec ID and SQL Exec Start):
SELECT report_id,
EXTRACTVALUE(XMLType(report_summary),'/report_repository_summary/sql/@sql_id') sql_id,
EXTRACTVALUE(XMLType(report_summary),'/report_repository_summary/sql/@sql_exec_id') sql_exec_id,
EXTRACTVALUE(XMLType(report_summary),'/report_repository_summary/sql/@sql_exec_start') sql_exec_start
FROM dba_hist_reports
WHERE component_name = 'sqlmonitor'
From my system I have
REPORT_ID SQL_ID SQL_EXEC_I SQL_EXEC_START
---------- --------------- ---------- ------------------------------
1022 fx439nus0rtcz 16777216 04/29/2015 13:34:15
1024 fjvsmy2yujbqd 16777216 04/29/2015 13:40:00
1025 9qn59dh1w8352 16777216 04/29/2015 13:41:12
1026 1uqrk6t8gfny8 16777216 04/29/2015 13:41:14
Using the REPORT_ID we can now extract the report in different format (HTML, TEXT, ACTIVE, XML) using DBMS_AUTO_REPORT.REPORT_REPOSITORY_DETAIL
SQL> set long 10000000 longchunksize 10000000 pages 0
SQL> SELECT DBMS_AUTO_REPORT.REPORT_REPOSITORY_DETAIL(RID => 1022, TYPE => 'text')
FROM dual;
SQL Monitoring Report
SQL Text
------------------------------
select count(*) from test_inmemory
Global Information
------------------------------
Status : DONE (ALL ROWS)
Instance ID : 1
Session : MPAGANO (12:35570)
SQL ID : fx439nus0rtcz
SQL Execution ID : 16777216
Execution Started : 04/29/2015 13:34:15
First Refresh Time : 04/29/2015 13:34:15
Last Refresh Time : 04/29/2015 13:34:15
Duration : .064582s
Module/Action : SQL*Plus/-
Service : orcl
Program : sqlplus@Mauros-iMac.local (TNS V1-V3)
Fetch Calls : 1
.....
or if we want it in flashy ACTIVE format
SQL> set trimspool on
SQL> set trim on
SQL> set pages 0
SQL> set linesize 1000
SQL> set long 1000000
SQL> set longchunksize 1000000
SQL> spool historical_sqlmon.sql
SQL> SELECT DBMS_AUTO_REPORT.REPORT_REPOSITORY_DETAIL(RID => 1022, TYPE => 'active')
FROM dual;

Several details are missing from this post (and from my knowledge of how the whole framework works) but I’ll make sure to pass them along as soon as I find out more.
Hopefully this blog post will be useful next time you are trying to figure out why a SQL ran so slow last weekend 🙂
UPDATE: DBA_HIST_REPORTS also includes SQL_ID, SQL_EXEC_ID, SQL_EXEC_START and several other information (concatenated together into a single column and separated by ‘3#’ sign) as basic columns KEY1, KEY2, KEY3 and KEY4. The following SQL provides the same information as the original SQL posted in this blog post
SELECT report_id, key1 sql_id, key2 sql_exec_id, key3 sql_exec_start
FROM dba_hist_reports
WHERE component_name = 'sqlmonitor'